Log Hunt writeup
Log Hunt writeup
pico CTFに入門してみました。
自分の復習も兼ねて問題のwriteup (解説) を書きます。
Writeup
問題文は以下の通りです。
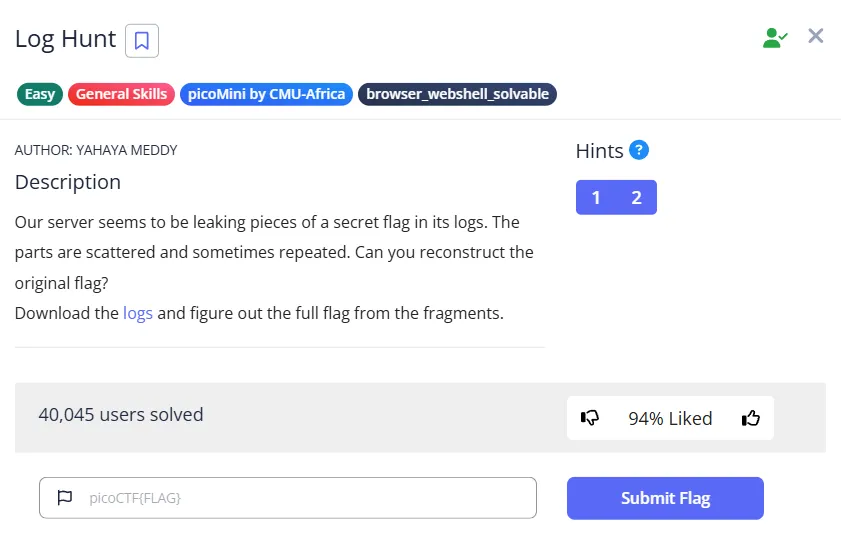
問題のログファイルへは問題文のリンクからダウンロードもできますが、CLIからダウンロードしてみます。
このCLIはpico CTFのCLIでもOKですし、ご自身のPCを利用してもOKです。
この問題は大丈夫ですが、ご自身のPCを利用する場合にはLinux環境を利用することをおすすめします。
Linux環境が用意しにくい場合にはpico CTFのCLIを利用してみてください。
以下はすべてUbuntu環境のCLIでの実行結果です。
wget https://challenge-files.picoctf.net/c_amiable_citadel/49cec6157142f24a599f4164d5b63322c2494f801390d6f22eb91b3aa592bc66/server.logダウンロードしたログファイルを確認してみます。
cat server.logcatコマンドの内容を確認すると、以下のような部分のログがあることがわかります。
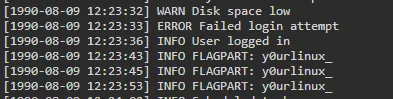
このログから、 FLAGPART という文字列がいかにも怪しそうです。
このログの中で FLAGPART という文字列が含まれている行を抜き取ってみます。
grep 'FLAGPART' server.log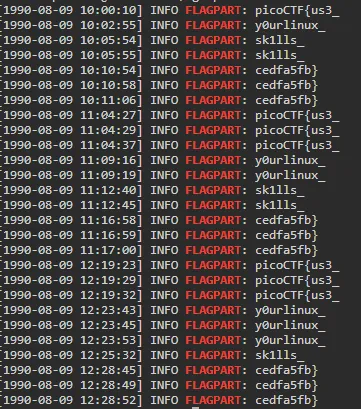
このログから何種類か重複してフラグの断片が記載されていることがわかります。
このまま抜き出して英語読みできる順に並べても良いですが、もう少しコマンドで整理します。
grep 'FLAGPART' server.log | awk '{print $NF}' | sort | uniq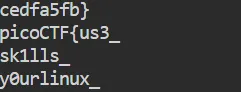
今はアルファベット順に並んでいるので、これを組み合わせて picoCTF{us3_y0urlinux_sk1lls_cedfa5fb} というフラグを入手できました。
コマンドの解説
使用したコマンドの簡単な解説をします。
wget
このコマンドは指定したURLからファイルをダウンロードするためのコマンドです。
wget <ダウンロードリンク>cat
このコマンドはファイルの内容を表示するためのコマンドです。
cat <ファイル名>grep
このコマンドは指定したファイルを対象に、指定した文字列を含む行を検索するためのコマンドです。
今回は FLAGPART という文字列を含む行を検索するために使用しました。
grep '<検索文字列>' <ファイル名>awk
awkは簡単な行ベースのテキストファイルを処理するためのコマンドです。
今回は最終フィールドの値を抜き取るために使用しました。
行をレコード、1行内の値をフィールドと呼び、下記のような関係になっています。
field1 field2 field3 # record1
field1 field2 field3 # record2
field1 field2 field3 # record3レコード全体は $0 で表され、フィールドは $1, $2, … で表されます。
今回は最終フィールドを抜き取るために $NF を使用しました。
awk '{print $NF}' <ファイル名>sort
このコマンドは指定したファイルの内容をソートするためのコマンドです。
今回はアルファベット順に並べるために使用しました。
sortuniq
このコマンドは指定したファイルの内容から重複する行を削除するためのコマンドです。
今回は重複するフラグの断片を削除するために使用しました。
uniq